

「ディープラーニング実践ガイド」の3章は移転学習についての補足説明です。
ディープラーニングがここまで流行している理由は以下の4つと挙げられてますが、一番の理由は4番目の訓練済みモデルの再利用、つまり移転学習だと言われています。
- ImageNetのような大規模で高品質なデータセットの出現
- 計算機環境の向上(高速で安価なGPUなど)
- モデルのアーキテクチャー、オプティマイザー、訓練手法などでのアルゴリズムの改良
- 数ヶ月かけて訓練したモデルを迅速に再利用可能であること
ここではいよいよデータセットを用意してモデルを改造することになりますね!AI開発している感が出てきてワクワクです!
データセットの準備
現時点では、本の資材で記載されている「downloaded dataset」の下記リンクは切れてます。
https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/download/train.zip
探したところ、データは見つかりましたが、直リンク貼れなかったので、少し紹介します。
まず「Dogs vs. Cats Redux: Kernels Edition」にアクセスします。アカウントが必要ですので、未登録の場合は登録しましょう。
ログインできましたら、上のリンクを踏むと次の画面に行けるはずです。
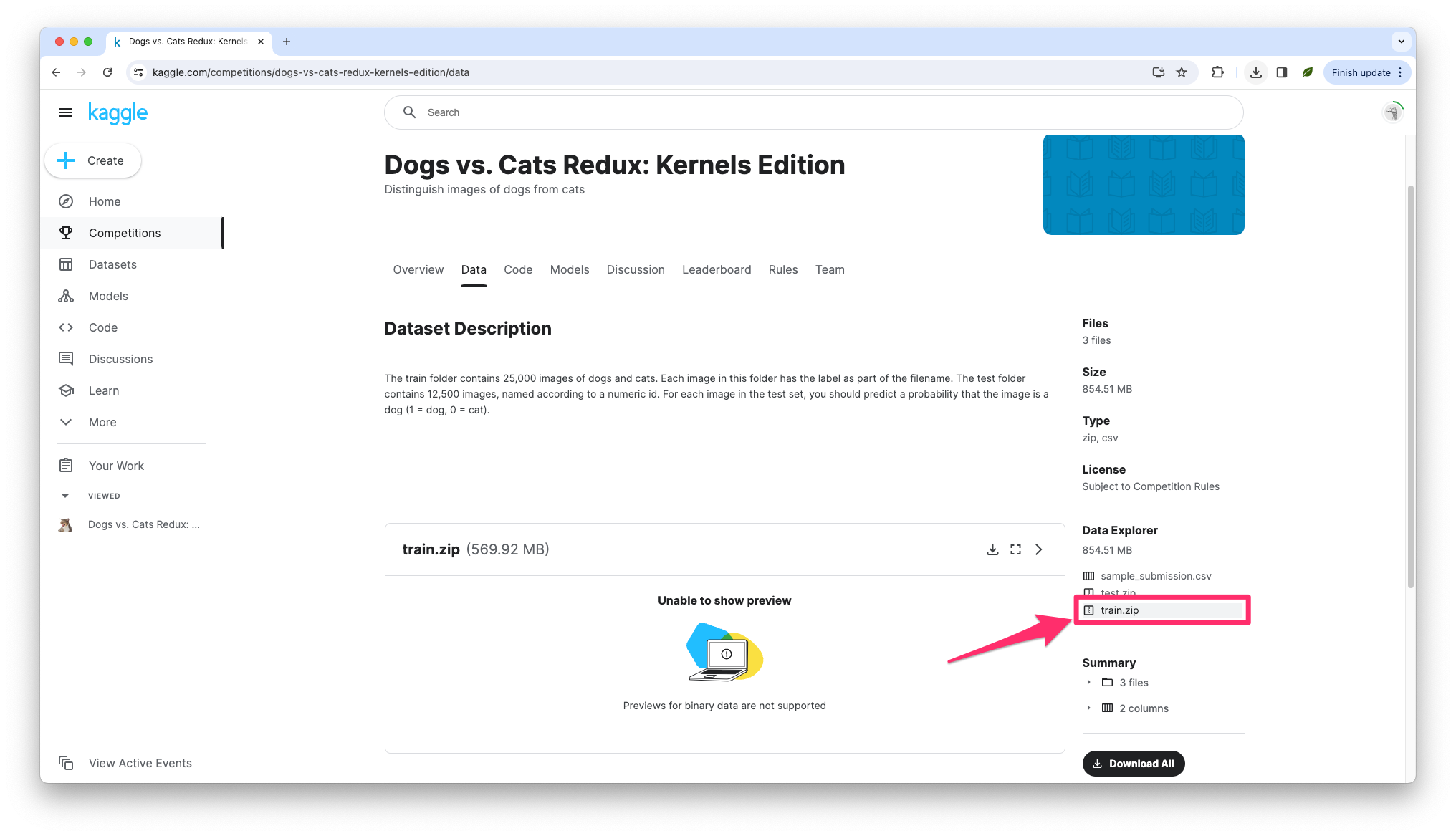
上のように、右下の「Data Explorer」から「train.zip」をクリックするとダウンロードできます。
あとはデータセットを訓練用と検証用に分ける作業ですが、本ではLinux/Macのコマンドで紹介されています。その通りにやればいけます。
Windowsではどうするだろうか、docker環境であればjupyter labのターミナルでいけるかもしれませんが、もしお困りでしたらコメントください。少し試せるかもしれません。
ソース修正と実行
「Practicode/chapter-3/1-keras-custom-classifier-with-transfer-learning.ipynb」を実行して行きますが、ソースと本の記載に少し食い違いがあり、2箇所ファイルパスの変更が必要です。
- 次のパス指定ありましたが、dataフォルダがあり、これをipynbファイルと同じ階層に配置することを考えると、本の記述が正しいと思います。
TRAIN_DATA_DIR = 'train/' VALIDATION_DATA_DIR = 'val/'次のようにパスを直してあげれば大丈夫のはずです。
TRAIN_DATA_DIR = 'data/train/' VALIDATION_DATA_DIR = 'data/val/' - このパスの階層は戻りすぎてます。
img_path = '../../../sample-images/dog.jpg'次のようにパスを直してあげれば大丈夫のはずです。
img_path = '../../sample-images/dog.jpg'
そうしましたら、次のように実行結果を確認できるではないかと思います。
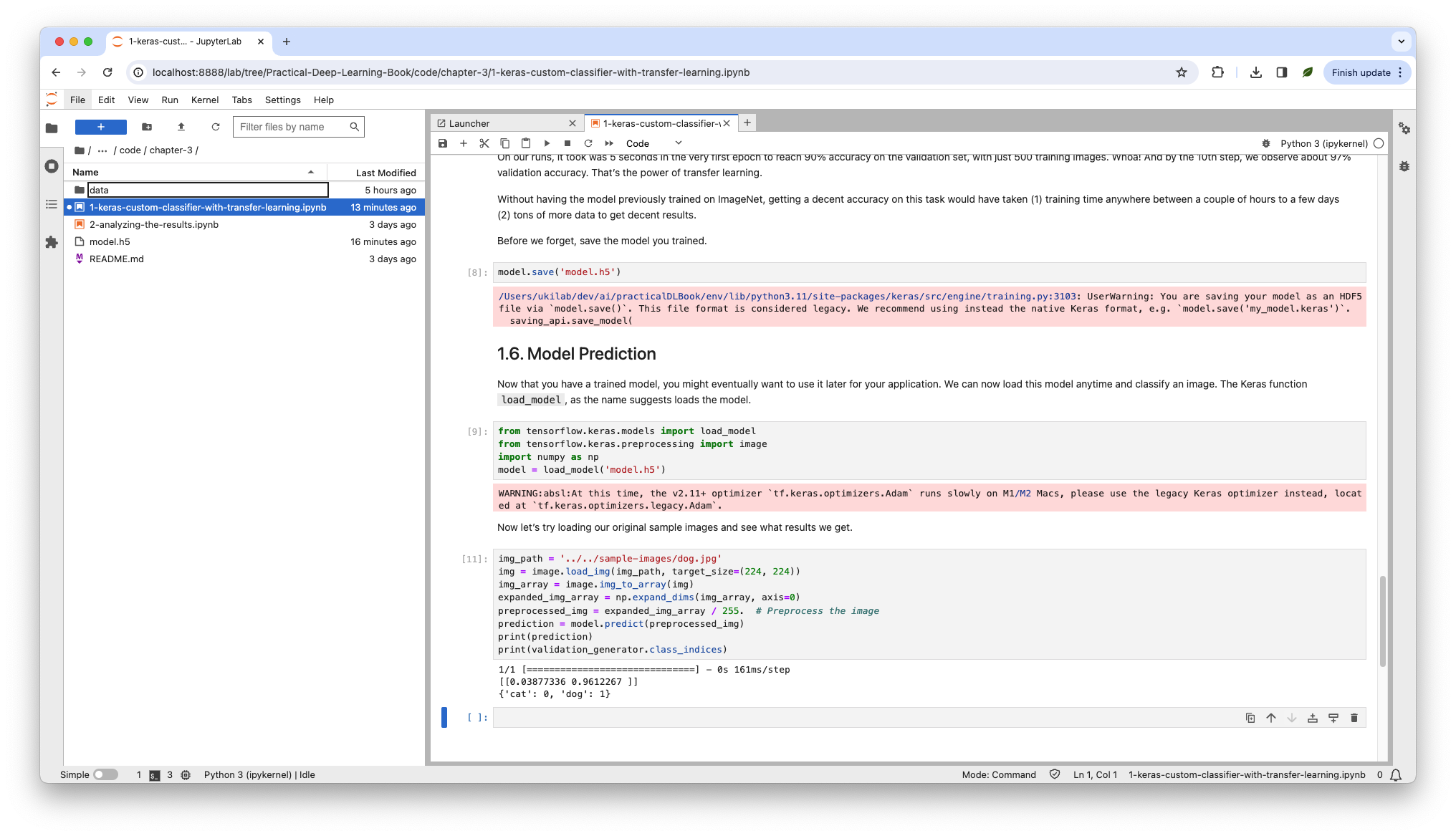
途中モデルの訓練は次のようになります。
「loss」は損失関数の値、「acc」は精度、「val_」付けられるものは検証の意味であるはずです。
最も注目すべき「val_acc」になるそうで、これは検証精度のはずです。
Epoch 1/10
8/8 [==============================] - 7s 867ms/step - loss: 0.6492 - acc: 0.7120 - val_loss: 0.1536 - val_acc: 0.9480
Epoch 2/10
8/8 [==============================] - 6s 791ms/step - loss: 0.2528 - acc: 0.8880 - val_loss: 0.1102 - val_acc: 0.9640
Epoch 3/10
8/8 [==============================] - 6s 790ms/step - loss: 0.1719 - acc: 0.9300 - val_loss: 0.0851 - val_acc: 0.9720
Epoch 4/10
8/8 [==============================] - 6s 818ms/step - loss: 0.1245 - acc: 0.9500 - val_loss: 0.0737 - val_acc: 0.9740
Epoch 5/10
8/8 [==============================] - 7s 856ms/step - loss: 0.0980 - acc: 0.9600 - val_loss: 0.0688 - val_acc: 0.9720
Epoch 6/10
8/8 [==============================] - 6s 822ms/step - loss: 0.0871 - acc: 0.9680 - val_loss: 0.0663 - val_acc: 0.9740
Epoch 7/10
8/8 [==============================] - 6s 800ms/step - loss: 0.0576 - acc: 0.9860 - val_loss: 0.0663 - val_acc: 0.9760
Epoch 8/10
8/8 [==============================] - 6s 805ms/step - loss: 0.0720 - acc: 0.9740 - val_loss: 0.0692 - val_acc: 0.9740
Epoch 9/10
8/8 [==============================] - 6s 849ms/step - loss: 0.0594 - acc: 0.9760 - val_loss: 0.0653 - val_acc: 0.9740
Epoch 10/10
8/8 [==============================] - 6s 817ms/step - loss: 0.0528 - acc: 0.9860 - val_loss: 0.0686 - val_acc: 0.9740
本では、この検証精度は回数に重なって上がっていきましたが、私の環境では、3回目でもう97%を超えており、そこからあまり変わってないです。
これは、今のモデルではこれぐらいのデータは3回ぐらい訓練すれば済む話だよという意味ですかね?!
結果は次のような感じで、96%の確率でこの画像は犬だと言ってますかね。
1/1 [==============================] - 0s 161ms/step
[[0.03877336 0.9612267 ]]
{'cat': 0, 'dog': 1}スクショには赤い部分もあるかと思いますが、H5の形式が古かったり、M1/M2だとAdamは遅いよだとかです。
とりあえず動作確認には支障がないようですので、とりあえずスルーです。
You are saving your model as an HDF5 file via `model.save()`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save(‘my_model.keras’)`.
the v2.11+ optimizer `tf.keras.optimizers.Adam` runs slowly on M1/M2 Macs
ソース解説
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Flatten, Dense, Dropout, GlobalAveragePooling2D
from tensorflow.keras.applications.mobilenet import MobileNet, preprocess_input
import math
TRAIN_DATA_DIR = 'data/train/'
VALIDATION_DATA_DIR = 'data/val/'
TRAIN_SAMPLES = 500
VALIDATION_SAMPLES = 500
NUM_CLASSES = 2
IMG_WIDTH, IMG_HEIGHT = 224, 224
BATCH_SIZE = 64
# 訓練用データを拡張
# 回転、ランダムシフト、ズームすることで画像データを増やします。
train_datagen = ImageDataGenerator(preprocessing_function=preprocess_input,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
zoom_range=0.2)
# 検証用データの準備、拡張はしない
val_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)
# 訓練用データのジェネレーターを生成します。
# 順番はシャッフルですが、何回実行しても同じ結果得られるようにseedを指定されてます。
train_generator = train_datagen.flow_from_directory(TRAIN_DATA_DIR,
target_size=(IMG_WIDTH,
IMG_HEIGHT),
batch_size=BATCH_SIZE,
shuffle=True,
seed=12345,
class_mode='categorical')
#検証用データのジェネレーター
validation_generator = val_datagen.flow_from_directory(
VALIDATION_DATA_DIR,
target_size=(IMG_WIDTH, IMG_HEIGHT),
batch_size=BATCH_SIZE,
shuffle=False,
class_mode='categorical')
def model_maker():
# 高速に実行できるようにMobileNetを利用
# 他の任意のニューラルネットワークについても適応できるはず
base_model = MobileNet(include_top=False,
input_shape=(IMG_WIDTH, IMG_HEIGHT, 3))
# すべての層を変更不可にする
for layer in base_model.layers[:]:
layer.trainable = False
input = Input(shape=(IMG_WIDTH, IMG_HEIGHT, 3))
custom_model = base_model(input)
# パラメーター数を減らす ※参考1
custom_model = GlobalAveragePooling2D()(custom_model)
# ノード数と活性化関数指定 ※参考2
custom_model = Dense(64, activation='relu')(custom_model)
# 過学習を防ぐため、ランダムで50%の出力を0にする ※参考3,4
custom_model = Dropout(0.5)(custom_model)
predictions = Dense(NUM_CLASSES, activation='softmax')(custom_model)
# モデル生成 ※参考5
return Model(inputs=input, outputs=predictions)
model = model_maker()
# 損失関数、オプティマイザー(学習率)、指標を指定
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['acc'])
# モデルを訓練
model.fit_generator(
train_generator,
steps_per_epoch=math.ceil(float(TRAIN_SAMPLES) / BATCH_SIZE),
epochs=10, # データセット全体に対する訓練回数を10回として指定
validation_data=validation_generator,
validation_steps=math.ceil(float(VALIDATION_SAMPLES) / BATCH_SIZE))
model.save('model.h5')
# 訓練したモデルをテスト
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing import image
import numpy as np
model = load_model('model.h5')
img_path = '../../sample-images/dog.jpg'
img = image.load_img(img_path, target_size=(224, 224))
img_array = image.img_to_array(img)
expanded_img_array = np.expand_dims(img_array, axis=0)
preprocessed_img = expanded_img_array / 255. # Preprocess the image
prediction = model.predict(preprocessed_img)
print(prediction)
# ラベルと番号を出力 ※参考6
print(validation_generator.class_indices)
延長
サンプル画像には猫の画像もあったかと思います。それを次のように試しました。
img_path = '../../sample-images/cat.jpg'
img = image.load_img(img_path, target_size=(224, 224))
img_array = image.img_to_array(img)
expanded_img_array = np.expand_dims(img_array, axis=0)
preprocessed_img = expanded_img_array / 255. # Preprocess the image
prediction = model.predict(preprocessed_img)
print(prediction)
print(validation_generator.class_indices)
# ※参考6
label_dict = validation_generator.class_indices
#最大の要素のインデックスを取得
a = np.argmax(prediction, axis=1)[0]
#インデックスから、ラベルを取得
keys = [k for k, v in label_dict.items() if v == a]
print(keys)実行結果は次のようになります。
1/1 [==============================] - 0s 39ms/step
[[9.9995565e-01 4.4392778e-05]]
['cat']問題なく猫だと判定できたようですね!
ちなみに、上記のよく分からないクラスを調べてみると、なんだかクラスごとに論文が1つ紐づいてる感じがします。
これまでにはこんな事ありましたっけ?コンピューターサイエンスってすごいことになってますね!
コメントを残す